VocalRip AI
I don’t know about you, but I love to sing karaoke on Saturday night. The problem is always in choosing a song – the old ones are already boring, but there are no new ones yet. It would be great if you could quickly make a karaoke version of any song in a couple of minutes. That’s exactly what the guys from Abyssmedia thought and released their VocalRip AI.
Main features
The program belongs to the novel neural networks aimed at separating musical sources. The main difference from alternative solutions is its compact size and excellent sound. And when I say excellent sound quality, it is not an exaggeration, but a fact.
The developers rate the SDR Vocals score at level 10 and this is close to the truth. Such scores are only available in online services for an additional fee. For example, SDR Vocal for the free Demux HT is slightly higher than 8.
In terms of size, this number is even more impressive. The installer takes up less than 30MB, while the free UVR takes up a full 1.5GB.
Performance can be considered average – the program used half the cores of my Risen 9. In my opinion, it would be possible to add settings and allow the user to choose how many resources to allocate to the program.
There is no hardware acceleration yet, but the developers promise support for DirectML in the next version. This will be very useful after the release of new processors with an NPU unit.
Interface
The interface is almost completely identical to AudioRetoucher, which we already reviewed earlier. It is intuitive, does not contain anything superfluous and scales perfectly on HighDPI screens.
Additional features
An interesting feature of the program is the ability to separately control the volumes of vocals and music after separation. If you are singing karaoke and have forgotten the words, then you can not completely remove the voice track and eavesdrop on the performer.
Saving separated audio tracks is possible in familiar audio formats, such as MP3, AAC, FLAC. To be honest, I didn’t even check it, since the free functionality was enough for me.
Conclusion
What do we have in the end? Another neural network for extracting and removing vocals from any song. Does it have any outstanding properties? I think yes. In terms of size-quality ratio, this is a real breakthrough.
Does she have any disadvantages? Of course. The complete lack of settings and hardware acceleration make it suitable for entertainment, and not for serious work.
VocalRip AI
14.95 USD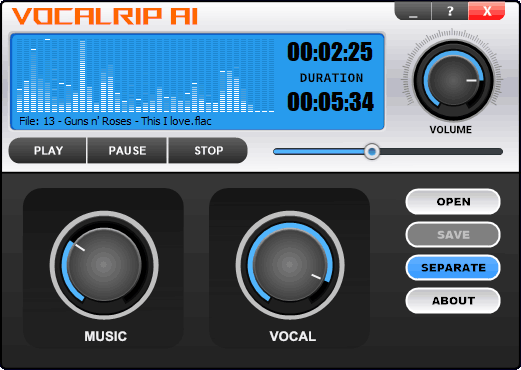
Pros
- Excellent audio quality
- Decent performance
- Compact size
Cons
- No hardware acceleration
- No settings



Recent Comments